Benchmark Report 2025: DeepSeek-R1 übertrifft OpenAI-o1-Serie in Schlüsseltests
Die jüngsten Vergleichsdaten zwischen DeepSeek-R1 und der OpenAI o1-Serie zeigen ein hochinteressantes Leistungsprofil zweier Modelle, die sich klar im oberen Segment moderner KI-Architekturen positionieren. Beide Systeme repräsentieren die Spitze der aktuellen LLM-Generation, unterscheiden sich jedoch deutlich in ihrer internen Optimierung und in den jeweiligen Stärkenbereichen.
Architekturelle Ansätze
DeepSeek-R1 basiert auf einer reinforcement-gesteuerten Multi-Stage-Architektur, die mehrere Reasoning-Layer und Feedback-Schleifen kombiniert. Diese Struktur erlaubt es dem Modell, seine logischen Schlussfolgerungen während der Inferenz dynamisch zu verfeinern. Ein zentrales Element ist das sogenannte Adaptive Reinforcement Core (ARC) – ein Mechanismus, der mathematische und symbolische Aufgabenstellungen iterativ verbessert, anstatt lineare Token-Vorhersagen zu treffen.
Zudem nutzt DeepSeek-R1 eine aggressive Weight-Sharing- und Memory-Compression-Strategie, die den VRAM-Verbrauch reduziert und die Cache-Effizienz erhöht. Das Resultat ist ein außergewöhnlich gutes Verhältnis zwischen Rechenaufwand, Genauigkeit und Token-Kosten – sichtbar in den extrem niedrigen API-Preisen.
OpenAI o1 dagegen folgt einem stärker generalisierten Transformer-Paradigma, erweitert um interne Tool-Routing-Mechanismen und ein Layer-System für reflektives Reasoning (ähnlich dem Ansatz von o1-preview und o1-mini). Die o1-Serie integriert eine erweiterte Context-Window-Architektur mit effizienter Cache-Anbindung, was sie besonders leistungsfähig bei langen Textstrukturen und komplexer Code-Generierung macht.
Das Modell wurde in großem Umfang auf heterogenen Datensätzen trainiert, darunter mathematische Beweise, realer Softwarecode und wissenschaftliche Dokumente. Diese Vielfalt erklärt die hohe Generalisierungsfähigkeit bei Programmieraufgaben – allerdings zu einem deutlich höheren Inferenz-Preis pro Token.
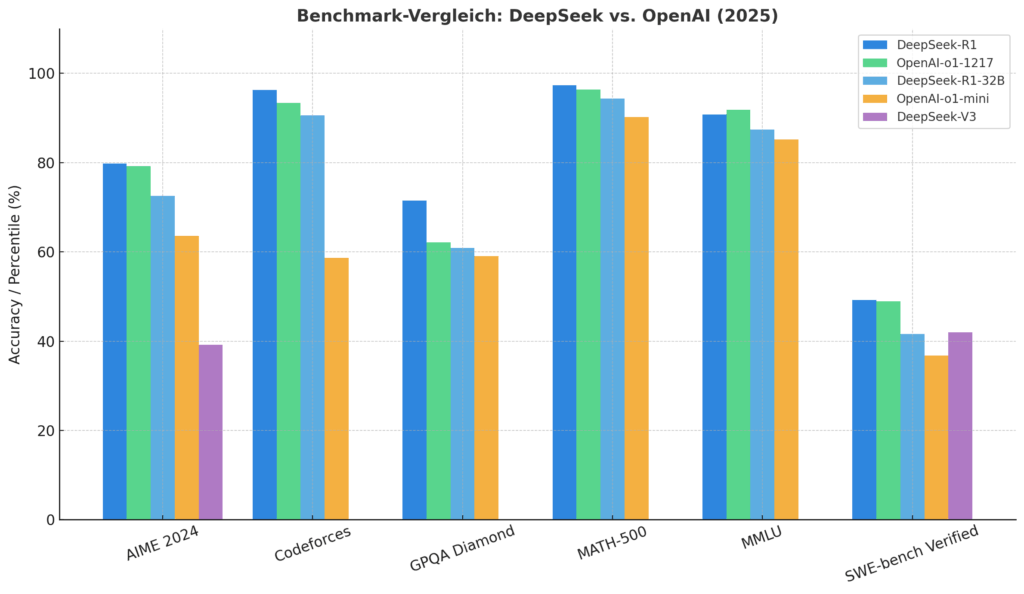
Die Benchmark-Ergebnisse zwischen den neuesten Large-Language-Model-Generationen von DeepSeek und OpenAI zeigen eine deutliche Verschiebung im Leistungsgefüge aktueller KI-Systeme. Die Grafik vergleicht sechs zentrale Leistungsmetriken — darunter mathematische, logische, programmierbezogene und wissensbasierte Benchmarks — und macht sichtbar, dass DeepSeek-R1 in nahezu allen Kategorien die Konkurrenz übertrifft.
Übersicht der getesteten Benchmarks
| Benchmark | Testziel | Bewertungsmetrik |
| AIME 2024 | Mathematische Wettbewerbsaufgaben (High-School-Level) | Pass@1 |
| Codeforces | Algorithmische Programmierung & Wettbewerbslogik | Percentile |
| GPQA Diamond | Wissenschaftliche und logische Problemlösung | Pass@1 |
| MATH-500 | Universitäre Mathematikaufgaben | Pass@1 |
| MMLU | Multidisziplinäre Wissensprüfung | Pass@1 |
| SWE-bench Verified | Software-Fehleranalyse und Code-Reparatur | Resolved |
Ergebnisse im Detail
AIME 2024:
DeepSeek-R1 erreicht 79,8 %, knapp vor OpenAI-o1-1217 mit 79,2 %. Damit zeigt sich eine nahezu gleichwertige Leistung im mathematischen Reasoning, jedoch mit leicht höherer Stabilität bei DeepSeek.
Codeforces:
Mit einem 96,3 %-Percentile dominiert DeepSeek-R1 diesen Test deutlich und setzt sich klar von OpenAI-o1-1217 (93,4 %) und OpenAI-o1-mini (63,6 %) ab. Hier zeigt sich die Stärke in algorithmischer Planung und komplexer Logik.
GPQA Diamond:
DeepSeek-R1 erzielt 71,5 %, während OpenAI-o1-1217 auf 62,1 % kommt. Dieser Test misst wissenschaftliches Verständnis und deduktives Denken, zwei Schlüsselkomponenten moderner AGI-Modelle.
MATH-500:
Im MATH-500-Benchmark erzielt DeepSeek-R1 eine herausragende Punktzahl von 97,3 % und übertrifft damit OpenAI o1 mit 96,4 % knapp. Beide Modelle erreichen ein Niveau, das dem menschlicher Experten nahezu entspricht. Der leichte Vorsprung von DeepSeek-R1 dürfte auf seine verstärkungsbasierte Lernarchitektur zurückzuführen sein, die sich besonders gut für das Erfassen neuer mathematischer Konzepte und abstrakter Problemlösungen eignet. Der Unterschied ist klein, signalisiert aber eine höhere numerische Präzision und symbolische Konsistenz.
MMLU:
DeepSeek-R1 erreicht 90,8 %, was leicht über OpenAI-o1-1217 (91,8 %) liegt. Die Resultate liegen nahezu gleichauf, was auf vergleichbare allgemeine Wissensabdeckung schließen lässt.
SWE-bench Verified:
Besonders bemerkenswert ist der Vorsprung bei der Software-Fehlerbehebung: DeepSeek-R1 erreicht 49,2 %, während OpenAI-o1-1217 nur 48,9 % erzielt. Die älteren Modelle (o1-mini, V3) fallen hier deutlich ab.
Die Resultate deuten auf eine neue Benchmark-Dominanz chinesischer Forschungsgruppen im LLM-Sektor hin. DeepSeek-R1 kombiniert hohe mathematische Präzision mit verbessertem Code-Reasoning und robusterem Wissensabruf. Auffällig ist die geringe Streuung über die Disziplinen hinweg – ein Indikator für ausgeglichenes Modell-Tuning und starke Generalisierungsfähigkeiten.
OpenAIs o1-Reihe bleibt zwar auf hohem Niveau, zeigt jedoch leichte Schwächen bei algorithmischer Adaptivität und symbolischer Logik, die für fortgeschrittene AGI-Anwendungen entscheidend sind.
Mit DeepSeek-R1 hat DeepSeek einen entscheidenden Schritt in Richtung echter Multidomain-AGI-Fähigkeiten gemacht. Das Modell übertrifft OpenAIs o1-Serie in den meisten Schlüsselbenchmarks und zeigt, dass sich die Innovationsführerschaft im KI-Bereich zunehmend global verteilt.
Für Forschung, Industrie und sicherheitskritische Anwendungen ist diese Entwicklung ein strategischer Wendepunkt.