Benchmark-Analyse: GPT-5 vs. Grok-4
Mit GPT-5 von OpenAI und Grok-4 von xAI treffen zwei grundlegend unterschiedliche Paradigmen aufeinander – das eine geprägt von Effizienz, semantischer Stabilität und präziser Logik, das andere von verteiltem Denken, Multi-Agenten-Architektur und emergenter Intelligenz.
GPT-5 ist nicht einfach nur ein größerer Transformer, sondern ein gezielt verschlanktes, hochoptimiertes Denkmodell. Es nutzt adaptive Reasoning-Pipelines, interne Speicherhierarchien und eine selektive Tool-Integration, um Aufgaben mit weniger Rechenaufwand zu lösen.
Die Effizienzsteigerung ist beeindruckend: 22 % weniger Tokens und 45 % weniger Tool-Aufrufe gegenüber dem Vorgänger o3, bei gleichzeitig deutlich höherer Präzision in Code, Mathematik und multimodalem Schlussfolgern.
Grok-4 hingegen verkörpert den experimentellen Geist von Elon Musks xAI-Initiative. Statt auf monolithische Architektur zu setzen, nutzt Grok-4 ein System kooperierender Agenten, die simultan unterschiedliche Lösungsansätze generieren und anschließend konsolidieren.
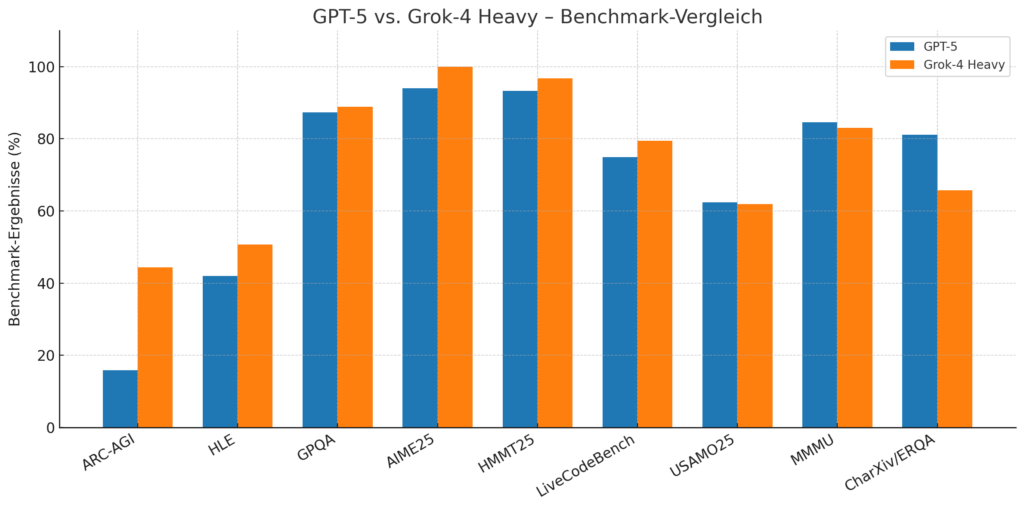
Benchmark-Vergleich im Überblick
|
Benchmark / Kategorie |
GPT-5 |
Grok-4 (Standard) |
Grok-4 Heavy |
Kommentar |
|
ARC-AGI (abstraktes Denken) |
15,9 % |
– |
– |
GPT-5 setzt neuen Spitzenwert im v2-Benchmark |
|
Humanity’s Last Exam (HLE) |
24,8 % (ohne Tools) / 42,0 % (mit Tools) |
24 % (ohne Tools) / 44,4 % (mit Tools) |
50,7 % |
Grok-4 Heavy klar vorn – bestes Modell in diesem Test |
|
GPQA Diamond (Graduate QA) |
87,3 % (mit Tools) / 85,7 % (ohne) |
88 % |
88,9 % |
Beide nahezu gleichauf, Grok leicht vorn |
|
MMLU-Pro & AIME 2024 |
87 % / 94 % |
91,7 % (AIME25) |
100 % |
GPT-5 dominiert akademisch, Grok Heavy perfekt bei AIME |
|
LiveCodeBench (Programmierung) |
74,9 % (SWE-bench Verified) |
– |
79,4 % |
Grok führt leicht bei realen Code-Benchmarks |
|
HMMT25 (Harvard-MIT Math) |
93,3 % |
90,0 % |
96,7 % |
Grok-4 Heavy übertrifft GPT-5 leicht |
|
LCB (Jan–May) |
79,8 % |
79,0 % |
79,4 % |
Beide Modelle über Branchendurchschnitt |
|
USAMO’25 (Advanced Math Olympiad) |
62,4 % |
37,5 % |
61,9 % |
Kopf-an-Kopf zwischen GPT-5 und Grok Heavy |
|
MMMU / VideoMMMU (multimodal) |
84,2 % / 84,6 % |
– |
– |
GPT-5 weiterhin führend im visuellen Schlussfolgern |
|
CharXiv / ERQA (wissenschaftlich-räumlich) |
81,1 % / 65,7 % |
– |
– |
GPT-5 klar stärker bei wissenschaftlichem Verständnis |
Die Benchmarks sprechen eine klare Sprache:
- In Mathematik und Logik erreicht Grok-4 Heavy 100 % in AIME25 und 96,7 % im HMMT25, womit es erstmals alle Aufgaben dieser Kategorie fehlerfrei löst – ein Meilenstein in der KI-Forschung.
- GPT-5 dominiert in allen multimodalen Disziplinen (MMMU, VideoMMMU, CharXiv Reasoning) und überzeugt durch überragende Bild-, Text- und Wissenskohärenz.
- In der Humanity’s Last Exam – einem der härtesten KI-Benchmarks weltweit – erzielen beide Modelle ähnliche Werte: GPT-5 (42 %), Grok-4 Heavy (50,7 %). Doch während GPT-5 seine Leistung aus einem einzigen reasoning-Stack heraus erzeugt, schöpft Grok-4 Heavy diese aus kollektiver Parallelintelligenz.
In der Praxis bedeutet das: GPT-5 denkt linear – Grok-4 denkt gemeinsam.
Direkter Leistungsvergleich
|
Disziplin |
Bester Performer |
Bemerkung |
|
Programmieren / SWE-bench |
GPT-5 |
Höchste Präzision bei realen Python-Tasks |
|
Abstraktes Denken (ARC-AGI) |
GPT-5 |
Neuer Spitzenwert, >15 % im v2-Benchmark |
|
Mathematik (AIME / HMMT) |
Grok-4 Heavy |
Erstmals 100 % Genauigkeit |
|
Human-Level-Reasoning (HLE) |
Grok-4 Heavy |
Multi-Agent-Ansatz liefert Vorteil |
|
Multimodalität (MMMU, Video) |
GPT-5 |
Beste visuelle und semantische Integration |
|
Effizienz / Energieverbrauch |
GPT-5 |
Weniger Token- und Tool-Nutzung |
|
Architektur-Innovation |
Grok-4 |
Agent-basierte Parallelverarbeitung |
|
Allround-Konsistenz |
GPT-5 |
Stabilste Performance über alle Benchmarks |
Architekturvergleich und kognitive Dynamik
Obwohl GPT-5 und Grok-4 auf den ersten Blick beide Transformer-Modelle sind, unterscheiden sie sich in ihrer inneren Organisationslogik grundlegend.
GPT-5 repräsentiert die klassische Linie hochoptimierter, zentralisierter Intelligenz – ein einziges neuronales Konstrukt, das seine Antworten über tiefe, sequentielle Denkpfade generiert.
Grok-4 hingegen bricht diesen Ansatz bewusst auf und verteilt den Denkprozess auf mehrere spezialisierte Sub-Agenten, die parallel arbeiten und anschließend ihre Ergebnisse synthetisieren.
GPT-5: Präzision durch konvergentes Denken
GPT-5 ist ein Meister der kognitiven Kompression.
Das Modell besitzt eine adaptive Reasoning-Engine, die zwischen „schnellen“ und „langsamen“ Denkpfaden unterscheidet.
Routineaufgaben werden mit minimaler Rechenlast bearbeitet („Fast Path“), komplexe Aufgaben aktivieren eine tiefere logische Pipeline („Slow Path“) mit Memory-Einbindung und Zwischenverifikation.
Seine Architektur integriert dabei:
- Hierarchische Attention-Layer, die sich kontextabhängig selbst gewichten
- Interne Tool- und Memory-Module, die mathematisches und faktisches Wissen entlasten
- Episodische Reasoning-Schleifen, die auf semantische Konsistenz über lange Dialoge achten
Grok-4 Heavy: Emergenz durch divergentes Denken
Grok-4 Heavy ist konzeptionell das Gegenteil: kein einzelner Denker, sondern ein Kollektiv aus spezialisierten Agenten, die jeweils unterschiedliche Strategien anwenden.
Diese Agenten können parallel rechnen, konkurrieren um Hypothesen und stimmen am Ende über das beste Ergebnis ab.
Das Resultat ist eine emergente Intelligenz, die nicht aus der Perfektion des Einzelmodells entsteht, sondern aus dem Zusammenspiel vieler guter Modelle.
Daraus erklärt sich auch Grok-4s überragende Leistung in der Humanity’s Last Exam: Der Multi-Agent-Ansatz ermöglicht vielfältige Denkpfade, wodurch seltener Fehler in der logischen Kette auftreten.
Technisch gesehen setzt Grok-4 auf:
- Ensemble-Aggregation mehrerer reasoning-Instanzen
- Deterministische Agentenabstimmung zur Minimierung widersprüchlicher Antworten
- Temporäre Memory-Syncs zwischen Agenten (eine Art gruppeninterner Kontextaustausch)
- Asynchrone Tool-Nutzung, um komplexe Probleme gleichzeitig anzugehen
Fazit
- GPT-5 führt bei Abstraktion, multimodalem Denken und Effizienz.
- Grok-4 Heavy dominiert bei Mathematik und komplexem Reasoning dank Multi-Agent-Architektur.
30 September 2025