Ein aktueller Vergleich führender Frontier-Modelle zeigt: Anthropic Claude Sonnet 4.5 positioniert sich in mehreren praxisnahen Benchmarks als das derzeit vielseitigste Sprachmodell – insbesondere im agentischen Codieren, Tool-Use und komplexem Reasoning.
Während GPT-5 in logischer und visueller Begründung weiterhin herausragende Werte erzielt, gelingt Claude 4.5 ein bemerkenswerter Sprung bei realitätsnahen Aufgaben mit Parallel-Compute und Multi-Step-Tool-Integration. Googles Gemini 2.5 Pro liegt dagegen in vielen Disziplinen deutlich zurück und überzeugt nur noch in einzelnen analytischen Szenarien.
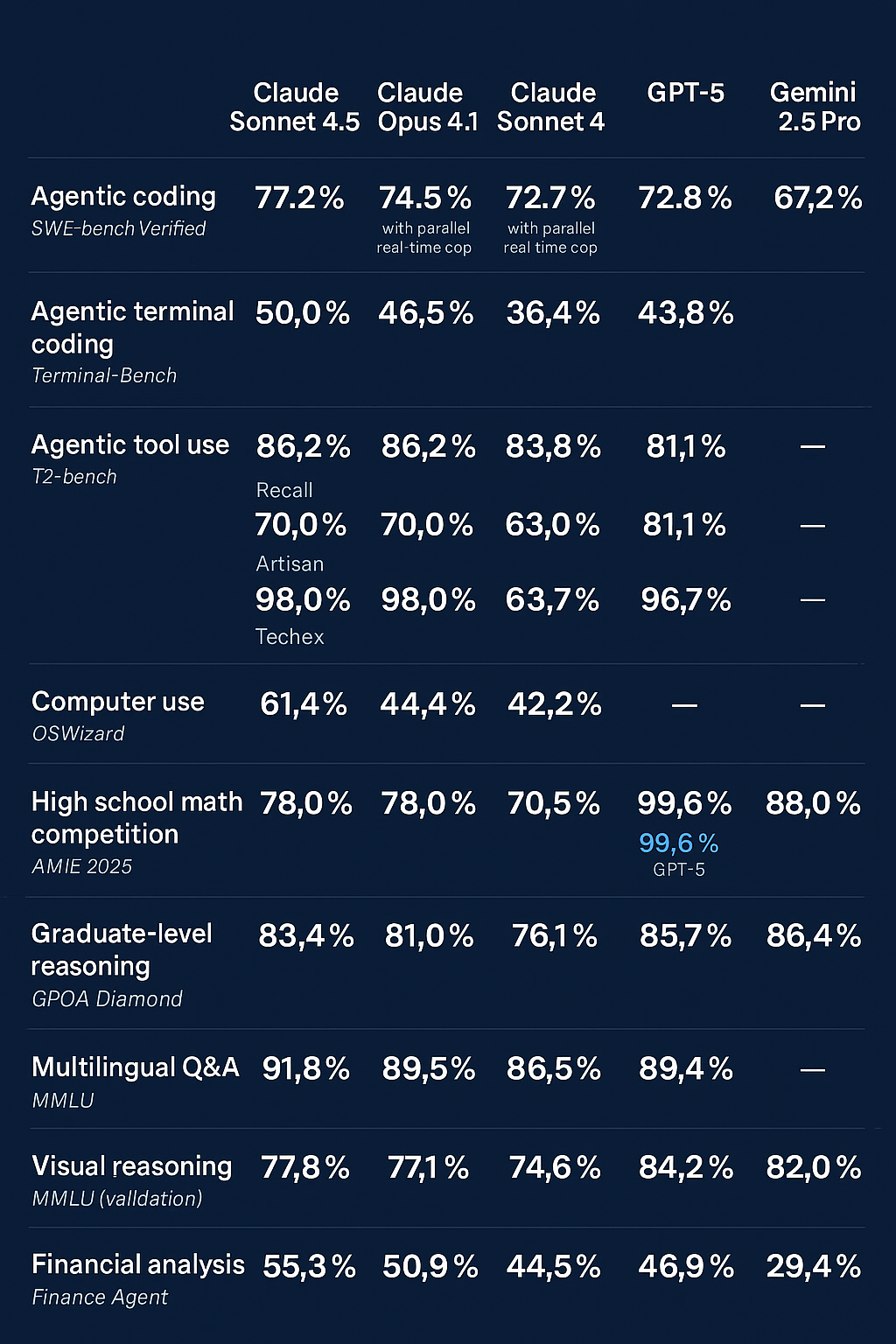
Agentic Coding & Terminal Use
In der SWE-Bench Verified erreicht Claude Sonnet 4.5 einen neuen Bestwert von 77,2 %, mit einem weiteren Anstieg auf 82 %, wenn paralleles Test-Time-Compute zugelassen ist. GPT-5 liegt mit 72,8 % (74,5 % Codex) spürbar darunter, Gemini 2.5 Pro sogar nur bei 67,2 %.
Beim praxisnahen Terminal-Benchmark zeigt sich die Dominanz ebenfalls: Claude 4.5 (50 %) übertrifft GPT-5 (43,8 %) deutlich – ein Hinweis auf bessere Prozesssteuerung und stabile Langkontext-Planung.
Tool-Use und Computersteuerung
Claude 4.5 führt den t2-Bench in den Kategorien Retail und Telecom mit bis zu 98 % an, was auf eine starke API-Interaktionsfähigkeit hindeutet. GPT-5 bleibt mit 96,7 % zwar dicht auf, Gemini 2.5 Pro liefert in dieser Disziplin jedoch keine verwertbaren Resultate.
Auch bei der Simulation realer Computerinteraktionen (OSWorld) erreicht Claude 4.5 mit 61,4 % einen klaren Vorsprung vor älteren Claude-Versionen – GPT-5 ist hier bislang ungetestet.
Mathematische und logische Kompetenz
In der AIME 2025-Challenge (High-School-Mathe) erzielt GPT-5 nahezu perfekte 99,6 % (Python), gefolgt von Claude 4.5 (100 % Python, 87 % no tools) und Gemini 2.5 Pro (88 %).
Im Graduate-Reasoning-Test (GPQA Diamond) liegen GPT-5 (85,7 %) und Gemini 2.5 Pro (86,4 %) knapp vor Claude 4.5 (83,4 %). Hier zeigt sich, dass OpenAI und Google in hochabstraktem akademischem Denken noch leicht die Nase vorn haben.
Sprachliche und visuelle Intelligenz
Beim multilingualen Verständnis (MMLU) erzielt Claude 4.5 mit 89,1 % Spitzenwerte – gleichauf mit GPT-5 (89,4 %) und vor Gemini.
In visueller Begründung (MMMU Validation) erreicht GPT-5 (84,2 %) erneut Bestwerte, während Claude 4.5 (77,8 %) und Gemini (82 %) dicht folgen. Damit bleibt OpenAI führend bei multimodaler Bild-Text-Integration.
Finanzanalyse & BWL-Anwendungen
Der Finance-Agent-Benchmark zeigt Claudes Stärke auch im wirtschaftlichen Kontext: 55,3 % bei Claude 4.5 gegenüber 46,9 % (GPT-5) und nur 29,4 % (Gemini 2.5 Pro). Für Business-Intelligence-Systeme oder Agent-basierte Reporting-Tools ist Claude 4.5 damit aktuell der neue Maßstab.
Fazit
- Claude Sonnet 4.5: Stärkstes Allround-Modell mit Fokus auf Agent-Use-Cases, Tool-Integration und praxisorientierte Reasoning-Tasks.
- GPT-5: Weiterhin führend in Mathematik, visueller Logik und akademischem Denken.
- Gemini 2.5 Pro: Technisch stabil, aber deutlich hinter den Bestwerten der Konkurrenz – speziell in Codierung und Finanztasks.