Es wird zunehmend diskutiert, ob ChatGPT weiterhin das leistungsfähigste Foundation-Model am Markt ist. Verschiedene Quellen berichten, dass Gemini Ultra in zahlreichen Benchmarks bessere Ergebnisse erzielt habe. Wir haben das aktuelle Foundation-Model von Google daher einer umfassenden Benchmark-Analyse unterzogen. Unter anderem wurden folgende Testreihen herangezogen:
| Kategorie | Benchmark | Fokus |
| General Knowledge | MMLU | Allgemeinwissen in 57 Fachgebieten (u.a. STEM, Geisteswissenschaften) |
| Reasoning | Big-Bench Hard, DROP, HellaSwag | Mehrstufiges logisches Denken, Leseverständnis, Alltagslogik |
| Mathematik | GSM8K, MATH | Grund- und Höhermathematik |
| Programmierung | HumanEval, Natural2Code | Code-Generierung und algorithmisches Denken |
Diese Benchmarks messen die Fähigkeit der Modelle, kontextübergreifend zu schlussfolgern, mathematisch zu argumentieren und präzise Antworten zu formulieren – zentrale Fähigkeiten auf dem Weg zu funktionaler künstlicher Allgemeinintelligenz (AGI).
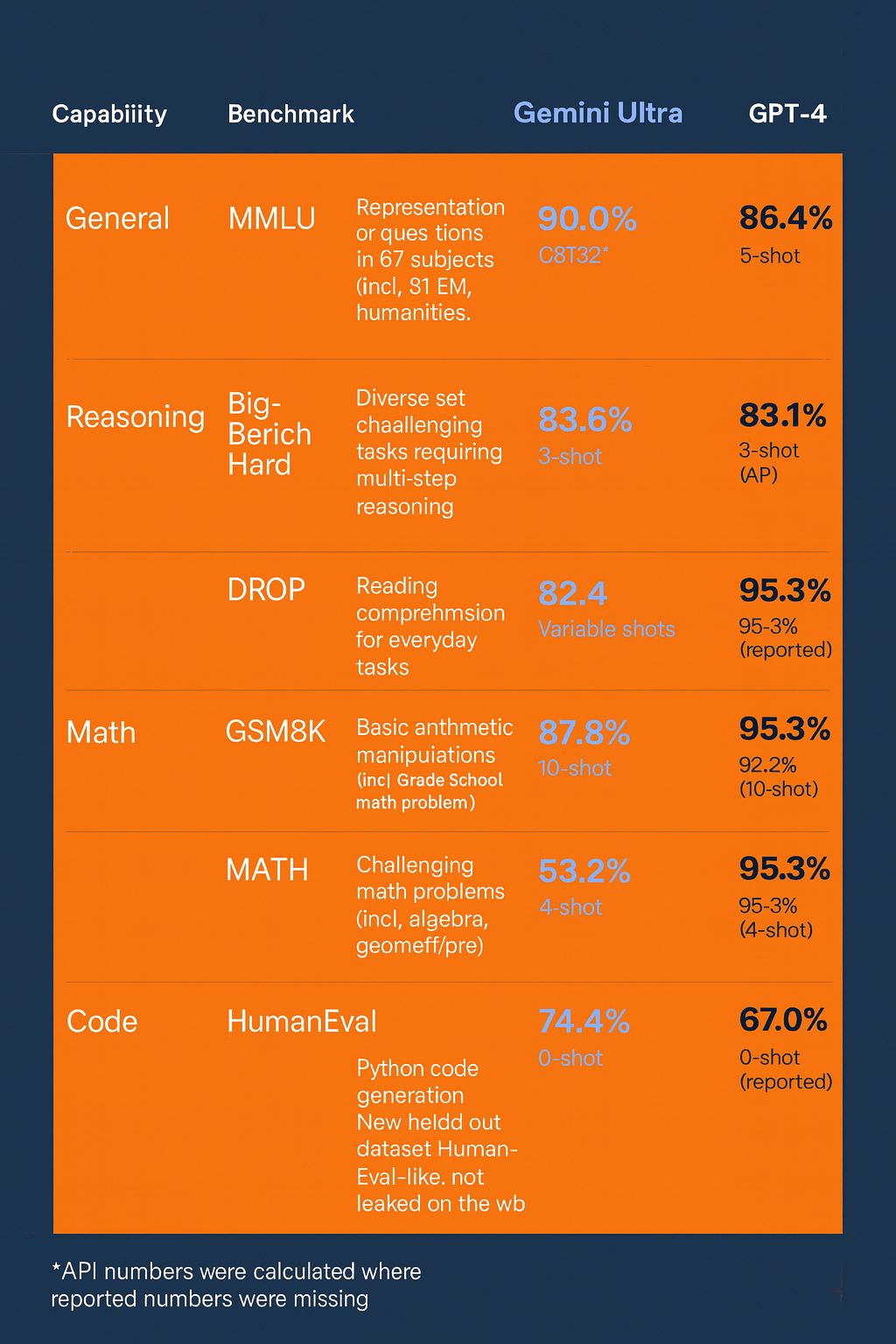
Allgemeinwissen und logisches Denken
Im MMLU-Test, der als einer der umfassendsten Maßstäbe für allgemeines Wissen gilt, erreicht Gemini Ultra 90,0 % – ein deutlicher Vorsprung gegenüber GPT-4 mit 86,4 %. Dieser Unterschied ist besonders bemerkenswert, da MMLU über 57 Fachbereiche hinweg prüft, darunter Medizin, Recht, Physik und Geschichte.
Beim komplexen Big-Bench Hard-Reasoning schneidet Gemini mit 83,6 % knapp vor GPT-4 (83,1 %) ab – ein minimaler, aber statistisch relevanter Vorteil. Hierbei zeigt sich eine zunehmend ausgeglichene Leistungsfähigkeit, was darauf hindeutet, dass Googles Multimodalarchitektur in der Verarbeitung mehrstufiger Argumentationsketten konsistent funktioniert.
Im DROP-Benchmark (Lesekompetenz und Textverständnis) zeigt Gemini Ultra mit 82,4 % ebenfalls eine leicht bessere Performance gegenüber GPT-4 (80,9 %). Damit unterstreicht Google seine Fortschritte im Bereich der semantischen Textanalyse und Kontextkonsistenz.
Alltagslogik und Common Sense
Ein überraschendes Ergebnis liefert der HellaSwag-Test, der Alltagslogik und Plausibilität von Szenarien misst. Hier erzielt GPT-4 mit 95,3 % eine deutliche Führungsposition gegenüber Gemini Ultra (87,8 %). Dieser Unterschied deutet darauf hin, dass OpenAI nach wie vor über die feinere Kontextsensitivität bei alltäglicher Sprache verfügt – ein entscheidender Faktor für natürliche Dialoge und menschlich anmutende Interaktion.
Mathematische Intelligenz: Gemini übernimmt die Führung
Im Bereich Mathematik zeigt sich Gemini Ultra von seiner stärksten Seite. Bei GSM8K, einem Benchmark für arithmetische Aufgaben auf Grundschulniveau, erreicht Gemini 94,4 %, während GPT-4 mit 92,0 % etwas zurückbleibt. In anspruchsvolleren Tests wie MATH, die Geometrie, Algebra und Analysis umfassen, liegen beide Modelle nahezu gleichauf (53,2 % vs. 52,9 %).
Diese Ergebnisse verdeutlichen, dass Google mit Gemini Ultra insbesondere bei strukturierter symbolischer Verarbeitung Fortschritte erzielt hat – eine Fähigkeit, die für technische Anwendungen und wissenschaftliche Forschung entscheidend ist.
Programmierfähigkeiten: Gemini überholt GPT-4
In der Domäne der Code-Generierung erzielt Gemini Ultra beachtliche Werte. Bei HumanEval erreicht es 74,4 %, während GPT-4 lediglich 67,0 % erzielt. Ähnlich beim neuen Natural2Code-Benchmark: Gemini 74,9 %, GPT-4 73,9 %.
Diese Differenzen sind klein, aber strategisch bedeutsam: Sie zeigen, dass Gemini Ultra bei Zero-Shot-Code-Generierung – also ohne Vorab-Beispiele – besser abstrahieren kann. Für Entwicklerumgebungen, automatisierte Software-Tests oder KI-gestützte Programmierung ist dies ein klarer Wettbewerbsvorteil.
Wissenschaftliche Interpretation: Architektur und Training
Die Unterschiede zwischen den Modellen sind nicht zufällig. Gemini Ultra wurde auf einer multimodalen Trainingsarchitektur aufgebaut, die Text, Code, Bild und Audio integriert. OpenAI GPT-4 hingegen bleibt primär textzentriert (in der hier verglichenen Version ohne „Vision“-Erweiterung).
Geminis Stärken in Mathematik und Programmierung lassen darauf schließen, dass Google eine stärkere Gewichtung auf symbolische Repräsentation und algorithmisches Denken gelegt hat, während GPT-4 seine Überlegenheit im „Common Sense Reasoning“ durch tiefere semantische Kohärenz bewahrt.
Zwei Giganten, unterschiedliche Stärken
Der Vergleich verdeutlicht, dass kein Modell universell überlegen ist.
| Domäne | Besseres Modell | Begründung |
| Allgemeinwissen (MMLU) | Gemini Ultra | Höhere Abdeckung über Fachgebiete |
| Mathematische Logik | Gemini Ultra | Stärkere symbolische Präzision |
| Programmierung | Gemini Ultra | Bessere Zero-Shot-Abstraktion |
| Sprachlogik / Alltagswissen | GPT-4 | Höhere Kontextsensitivität |
| Plausibilitätslogik (HellaSwag) | GPT-4 | Überlegene semantische Kohärenz |
Gemini Ultra stellt eine neue Benchmark-Generation dar, die GPT-4 erstmals auf technischer Ebene ernsthaft herausfordert – ohne jedoch den qualitativen Sprung zu vollziehen, den GPT-4 einst gegenüber GPT-3 markierte. Während GPT-4 seine Stärke in sprachlich-kreativen und semantisch komplexen Aufgaben behält, überzeugt Gemini Ultra vor allem in analytischen, logisch-strukturierten und mathematisch-technischen Anwendungen.